
Generative AI is beginning to change how risk intelligence teams work. When we asked analysts earlier this year how they use generative AI, writing and summarization topped the list. At the GSX security conference this fall, several tools launched new AI-powered features, including our own at Factal.
For overworked security and risk teams, these features can be a big time saver. They also help team members who find clear and concise writing challenging, particularly as real-time information becomes more noisy than ever. But AI can also introduce its own noise and inaccuracies. As AI models improve, the risks are more nuanced than hallucination. They’re harder-to-detect errors that can creep into your work, which can reflect poorly on your team’s credibility.
At Factal we took a careful, thoughtful approach to building a summarization tool. It draws from our verified updates and editorial guidance to create a high-quality first draft. In this example, it created an up-to-the-minute summary of Hurricane Helene from hundreds of Factal verified updates:
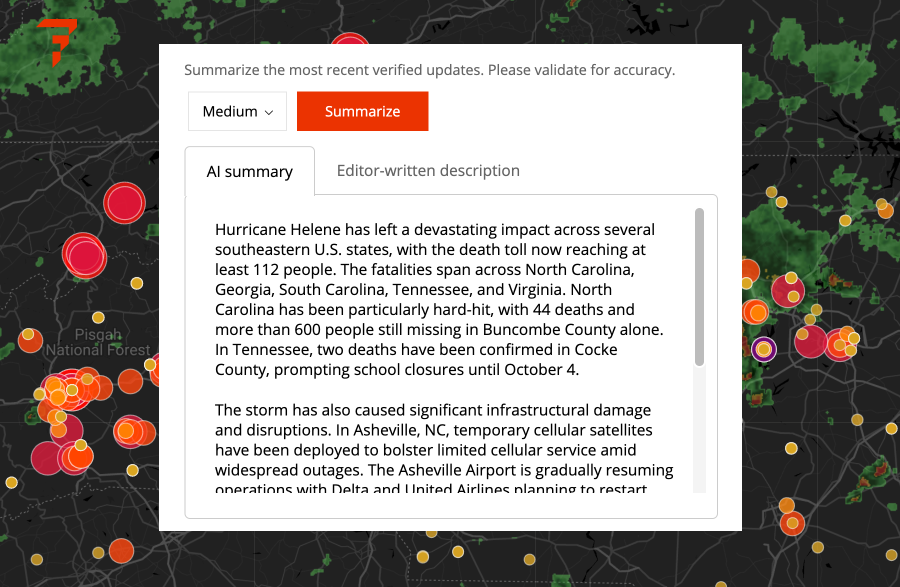
After months of testing, we identified several key pitfalls that took some work to minimize. AI mistakes are never eliminated entirely, and that’s why you should always check your work. In the realm of risk intelligence, the stakes are high — errors can compromise employee safety, trigger regulatory complications or create financial exposure. We’re sharing these pitfalls to help analysts who work with generative AI to better spot and avoid them:
⇨ A great way to get started with AI in global security is our free white paper, “A practical guide to AI in risk intelligence.” I’ll also be speaking at the OSAC Annual Briefing in November.
Poor source material
AI responses rely on the quality and accuracy of the information it has to work with. If you feed social media chatter into a generative AI modeI, you’ll get a summary of the chatter along with any speculation that came with it. (As we discuss in “presentation bias” below, the act of running it through an AI can make it feel more credible.) If the model is faced with conflicting information, it struggles at squaring it, and often treats sources as if they all carry equal weight. We’re careful at Factal to limit AI summarization to real-time information verified by our editors. If there’s a mistake in our coverage, we publish a correction. When there’s conflicting details, we include editor’s notes that help the model evaluate the sources and clearly communicate which details are in conflict.
Information vacuums
AI models aim to please. If you feed insufficient information to an AI, it’s more than happy to try to fill in the gaps either from its own training or the open internet. This can introduce all kinds of errors. When a model searches the internet for an answer, it can be a crapshoot: it consults a handful of sources, and the quality and timeliness of those sources vary. AI models perform best when you provide them ample data and instruct them to stick to the source material provided.
Lack of background context
Similarly, if you ask a model to summarize the latest developments in a long-running conflict, it will fall back on its training data to understand the backstory. However, training data is time-delayed by several months, so there’s a chronological gap. You also inherit any bias in training data, such as different regional perspectives. Sometimes it works well, other times the model overgeneralizes or mis-contextualizes an answer. At Factal, we provide event background information written by our editors to ground the model correctly.
⇨ To provide supporting information to an AI model like ChatGPT, you can either include it in the prompt itself or attach documents to the prompt. But make sure your data is not helping train a public model. Here’s how to turn it off in ChatGPT.
Spurious correlation
AI models excel at summarizing a single event. But ask it to contextualize the latest news about APAC, for example, and it will attempt to weave unrelated information together into a single narrative. (Humans do the same thing, right?) Sometimes this is harmless clustering, like a newscast that bundles similar stories together. Other times it infers – or outright declares – a correlation between them. The best anecdote is narrowing the scope (i.e. weather in Southeast Asia) and providing as much detail as possible in the prompt to focus the response.
Sensitivity to speculation
A related issue is AI models often take speculative leaps to improve the narrative. For example, a story about a single protest against the government may be described as a growing government backlash. This is often compounded by the next pitfall…
Dropped attribution
AI models regularly drop journalistic attribution from news stories when asked to summarize them. In the example below, the AI summary of an arrest in New Jersey stripped out all of the police attribution (“police say”) from the originating news story. Suddenly an allegation became fact. Journalistic attribution is not only good writing, but it also provides legal protections. We’ve found even with careful training, AI models will occasionally skip over attribution from input material to tighten the narrative, so it’s a good idea to double-check the results.

Escalation fallacy
One of more surprising pitfalls is how AI models conflate the volume of information with events on the ground. For example, if the volume of news reports on the Russia-Ukraine war increases, models will often assume that means the conflict has escalated or intensified. It doesn’t help that news headlines often add a little hyperbole to the mix. Keep an eye out for any unsupported implication that a critical event has grown in intensity.
Persistence bias
If you instruct a model to summarize a news event that recently concluded – but the source material does not indicate that the event has concluded – it will assume it’s still ongoing. This is also a journalistic tendency: news organizations publish fewer stories about an event’s improvement or conclusion than its outset. Watch the verb tense in AI summaries to minimize confusion.
Presentation bias
Studies have found there’s a tendency for some people to assume an automated response has more credibility. This is especially the case when a security tool provides an AI response, rather than asking Chat GPT directly. The tool may have an air of authority, and you may assume that the response has been validated by humans. But every AI response should be double-checked for accuracy. At Factal, we decided to not auto-generate AI summaries, but give the user control to customize them individually. This gives the user a sense of accountability and increases the likelihood they’ll validate the response. We’re also careful to label AI features clearly.
In the last year alone, AI models have improved significantly, but they still make mistakes. As we’ve seen, these mistakes aren’t as obvious as blatant hallucinations. In many ways, these errors are more damaging because they’re more difficult to spot. They can creep into situation reports, strategic decks and annual risk assessments. Sometimes they’re minor mistakes, but once a team has the reputation of over-relying on AI, their credibility is called into question. It’s a hard label to shake.
Once a team has the reputation of over-relying on AI, their credibility is called into question.
One of the biggest opportunities for security teams in an era of information pollution is to become the source of truth in their organizations. Trust is what matters most. AI is an important tool to enhance and accelerate our work, but as an assistant, not a shortcut. By using AI thoughtfully and staying vigilant against its pitfalls, security teams can lead with accuracy and preserve the trust they’ve earned in their organizations.
(To see Factal’s AI features in action, please visit Factal.com for a personalized demo. To learn more about AI, download our free white paper, “A practical guide to AI in risk intelligence.” Header photo by Amador Loureiro on Unsplash.)